
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- TensorFlow
- webscrap
- kafka설치
- topic생성
- 코딩생활
- DataFrame
- find()
- to_json
- read_excel
- iloc
- read_table
- 강남데이트
- findall()
- 녘
- to_html
- 갈비스테이크
- groupby
- find_all()
- 웹스크랩
- keras
- to_csv
- to_excel
- read_fwf
- 강남 녘
- select_one()
- pandas
- read_csv
- Join
- pivot_table
- select_related()
- Today
- Total
자드's
[ Pandas ] Python의 pandas 라이브러리를 이용한 데이터분석의 기초 ( Series, DataFrame ) - (3) : 파일로 저장하기, 불러오기 본문
[ Pandas ] Python의 pandas 라이브러리를 이용한 데이터분석의 기초 ( Series, DataFrame ) - (3) : 파일로 저장하기, 불러오기
최자드 2022. 11. 7. 23:32DataFrame : File input / output

작성한 DataFrame을 파일로 저장하거나
작성된 파일을 불러와서 DataFrame으로 저장하는 일은
데이터 분석에서 필수 업무 중의 하나이다
오늘은 몇몇 형태의 파일을 불러오거나 저장하는 방법을 알아보자
CSV(.csv)파일 불러오기 : read_csv( )
pandas.read_csv( ' 경로 ' ) 형식으로 사용이 가능하다
편의상 pandas를 pd로 축약해서 쓰고있다
import pandas as pd
from pandas.tests.frame.methods.test_sort_values import ascending
df = pd.read_csv("../testdata/ex1.csv")
print(df,type(df))
print()
df = pd.read_table("../testdata/ex1.csv", sep=',', # 텍스트 파일을 읽어오는 read_table 로 읽어올 때는 구분자(sep)를 부여해줘야함
skipinitialspace=True # 공백 없애기 skipinitialspace=True
)
print(df,type(df))
print()
df = pd.read_csv("../testdata/ex2.csv", header=None,
names=list('korea')
)
print(df)
read_table 메소드로 파일을 불러올 때는
sep (separate) 구분자를 써줘야한다
불러왔을 때 구분자가 없다면
' , ' 가 columns 사이에 붙어있기 때문이다
| read_table("../testdata/ex1.csv") sep=',' 구분자 없을 때 |
read_table("../testdata/ex1.csv", sep=',') sep=',' 구분자 있을때 |
 |
 |
Text(.txt)파일 불러오기 : read_csv( )
마찬가지로 .txt 파일도
pd.read_csv( ' 경로 ' ) 형식으로 사용이 가능하다
skiprows 옵션을 사용해서
읽어오지 않을 rows를 제외할 수 있다
df = pd.read_csv("../testdata/ex3.txt", # txt파일은 csv로 읽을 수 있음
sep='\s+', # sep=정규표현식
skiprows=[1,3] # 1,3행 제외
)
print(df)
pd.read_fwf( ' 경로 ' ) 형식으로
.txt 파일을 불러올 수 있는데
형식없이 작성되어 있는 텍스트를
구조화해서 불러오는것이 가능하다
widths로 분할을 하고
names로 columns의 이름을 부여해서 불러온다
df = pd.read_fwf("../testdata/data_fwt.txt", header=None,
widths=(10,3,5), # widths=(10,3,5) 붙어서 나오는 글자를 나누기
names=('date','name','price') # columns에 이름을 부여
)
print(df)| 일반 텍스트로 형식 없이 작성된 모습 |
read_fwf( ) 메소드를 통해 옵션을 부여해서 가져온 모습 |
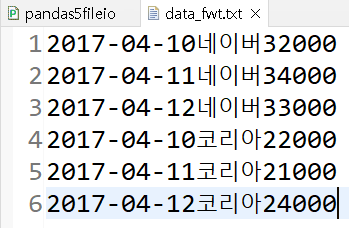 |
 |
크기가 큰 파일을 불러오기 : chunk
많은 양의 데이터가 들어있는 파일을 불러올 때는
chunksize 옵션을 통해서 잘라내어 불러올 수 있다
이는 메모리 절약차원에서 사용하는 방법이다
반복문을 통해서 분할 된 데이터를
원하는만큼 꺼낼 수 있다
보통의 데이터 파일들은 적지 않은 양을 가지고 있으므로
매번 모든 데이터를 불러오면 메모리 낭비가 될 수 있는데
chunksize 옵션은 이를 예방해줄 수 있는 좋은 방법이기 때문에 알아두도록 하자
print('chunk : 파일의 크기가 큰 경우 일정 행 단위로 끊어 읽기') # * 알아두자~ *
test= pd.read_csv("../testdata/data_csv2.csv", header=None,
chunksize=3 # 3개씩 끊어읽기 (메모리 절약 차원)
)
print(test)
print('------')
for piece in test:
print(piece.sort_values(by=2, ascending=True)) # 2번째 열 내림차순 정렬(청크 단위)| 분할 전 | 분할해서 반복문을 통해 꺼낸 모습 |
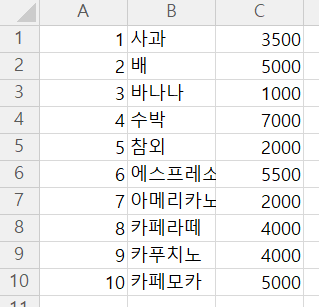 |
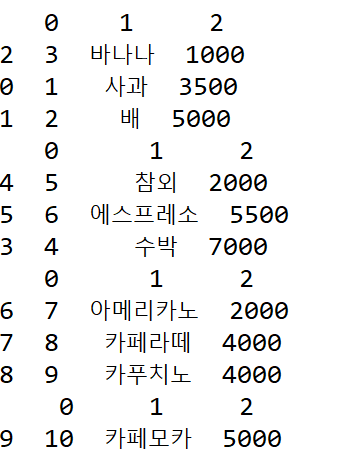 |
파일 저장하기
파일을 저장하는 법도 간단하다
많이 쓰게될 저장법을 보자면 대표적으로
to_html( ), to_csv( ), to_json( ) 등이 있고
괄호 안에 저장경로만 지정해주면 된다
items = {'apple':{'count':10, 'price':1500}, 'orange':{'count':5, 'price':1000}}
df = pd.DataFrame(items)
print(df)
df.to_clipboard() # 클립 보드에 저장
print(df.to_html()) # html로
print(df.to_csv()) # csv로
print(df.to_json()) # json으로
print()
df.to_csv('result1.csv')
df.to_csv('result2.csv', index=False, sep=',')
df.to_csv('result3.csv', index=False, header=False, sep=',')
Excel(.xlsx) 파일 저장 및 불러오기
엑셀파일로 저장하는데에는 writer가 필요하다
pd.Excelwriter( ' 경로 ' , engine = ' xlsxwriter ' ) 의 형식으로
writer를 만들어 준 후에
to_excel ( writer , sheet_name = 시트이름) 메소드를 이용하고
writer.save() 메소드를 사용해 저장을 완료하면 된다
파일을 읽어올 때는 위의 다른 방법들과 동일하게
pd.read_excel ( ' 경로 ' , sheet_name = 시트 이름 ) 사용해 불러오면 된다
items = {'apple':{'count':10, 'price':1500}, 'orange':{'count':5, 'price':1000}}
df = pd.DataFrame(items)
print(df)
writer=pd.ExcelWriter('result5.xlsx', engine='xlsxwriter') # writer 작성
df.to_excel(writer, sheet_name='test') # df를 엑셀로
writer.save() # 저장
print()
myexcel = pd.read_excel('result5.xlsx', sheet_name='test')
print(myexcel)
파일로 불러오기와 저장하기는
매우 간단한 방법이지만
필수로 요구되는 작업이기 때문에
꼭 기억을 해놓아야 한다
다음 포스팅에서는 저장되어있는 파일 말고
웹에서 데이터를 불러오는 방법을 연습할 것이다
방대한 양의 데이터가 존재하고 있는 웹에서
데이터를 가져오는 것 또한
매우 중요하고 필수적인 요소이다
원래 이번글에서 모두 다루려고 했지만
내용이 많아서 분할을 했다
꼭 복습하도록 하자


